According to reports, 80% of the data is visual. Companies like Google and Microsoft use Visual Language Models (VLMs) to comprehend it better. Such VLMs would enable learning from images as well as texts. It has some assistance for visual questions and captions of a given image. The invention would probably transform the way we use computers and find information. It is also essential for developing virtual location managers and the vlm software package.
Google uses VLMs in products like Google Lens, which identifies objects and relays information about them. Similarly, Microsoft also incorporates VLMs within Azure Computer Vision for the development of applications capable of understanding visual data by the end developer. The use of vlms and vlm software is gaining currency. Understanding how these work and what their applications could prove to be an interesting thing. VLMs and virtual location managers could turn many industries upside down-from e-commerce to health care. The price impacts would be huge. But more exciting uses of VLMs will come as they improve further. Hence, this looks like an exciting time for vlm software and visual AI.
Understanding the Fundamentals of Visual Language Models
Visual Language Models (VLMs), which is an AI type. It aids computers to interpret visual data. These models have three main components: a vision encoder, an embedding projector, and a text decoder. The vision encoder takes care of all the visual data-inputs like images or videos. The embedding projectors are those which would ensure both of them (visual and textual data) correspond well. This would then generate words using the garner hence it is a decoder.
Core Components of VLMs
The architecture of VLMs includes three concepts: the vision encoder to take care of visual data; the embedding projector linking visual and textual data, hence the model understands both. It will generate an output in text from the input that is put into it. Therefore, it could describe or caption the visual data.
Visual Processing AI over the Ages
AI visual process techniques have been evolving over time and now much more improved and enhanced VLMs have entered the world. They learn on large data sets and get smarter with time. This new development has made possible virtual location management services along with virtual location strategy. They help to serve various sectors like e-commerce and healthcare.
One of the present usages of vlm technology applies on the better business outcomes it generates, such as virtual location management services which assist in inventory-tracking activity, whereas virtual location strategy enhances logistical and supply chain management.
The Revolutionary Impact of VLMs on Digital Vision
VLM’s change all of lousy, never-ending questions that we ask and interact with digital devices. They make the life of a computer understand and use visual data, thus facilitating increased accessibility improvements usage and even boosts efficient use. VLm solutions, among others, form the core technologies for innovating future tools such as intelligent eyewear and self-driving cars.
Working as mileages in bringing improvements regarding the so many advantages that accrue from the VLM technology, it is a major game-changer in digital vision. Some of the high end among many other ones you can find include;
- Improved accessibility: VLMs have enabled most disabled people to use digital devices easily.
- Better user experience: Using VLMs, devices become more intuitive and really fun to use.
- Increased efficiency: VLMs automate tasks and things become productive and efficient.
We need vlm tools to create and use vlm tools, such as deep learning and computer vision; with them, we can generate new VLM solutions. They redefine the way we use digital devices and find information.
Indeed, the impact of VLMs on digital vision is great because they truly have the potential to change the way we use digital devices and search for information.mation is endless. As VLM tech keeps getting better, we’ll see even more cool uses and solutions in the future.
| VLM Benefits | Description |
|---|---|
| Improved Accessibility | VLMs make it easier for people with disabilities to use digital devices. |
| Enhanced User Experience | VLMs make using devices more intuitive and fun. |
| Increased Efficiency | VLMs automate tasks, making things more productive and efficient. |
You May Like: What's A Webhook And How Does It Work? With Examples
Technical Architecture of Modern VLMs
These complex neural networks are modern VLMs. Computing power is the must use that virtual local machines can provide facility via virtual machine software. These virtual local machines create virtual environments and then provide very simple, scalable, manageable virtualization tools.
The architecture of VLMs contains the following important parts:
- Neural base of Neural Networks: Convolutional and Recurrent Neural Networks work hand in hand to learn perceptual patterns and relationships between visual data and text.
- Data Requirements for Training: Each VLM model usually requires training on mammoth amounts of data, typically millions of images and texts.
Processing Pipeline Overview: The processing pipeline consists of many stages, including data preprocessing, feature extraction, and model training, which all need enhancement using virtualization tools.
| Component | Description |
|---|---|
| Neural Network Foundations | Convolutional Neural Networks (CNNs) and Recurrent Neural Networks (RNNs) |
| Training Data Requirements | Millions of images and texts |
| Processing Pipeline Overview | Data preprocessing, feature extraction, and model training |
How VLMs Process and Interpret Visual Information
They use computer vision, deep learning to condense all the beautiful works in images and videos. These models can spot the objects, scenes, and actions represented in visual data.
These models are trained according to the characteristics they extract from each other. Recognizing appropriate patterns and relationships is another significant feature in the visual with textual data interpretation. Virtual environment solutions, along with cloud computing services, play the most vital role in deploying and managing such models. Efficient handling of big datasets becomes easy now.
Some of the advantages of VLMs would be:
- Higher precision in recognizing images and videos
- Better way to extract useful details from visuals
- An approach that improves efficiency in processing and analyzing vast datasets
With cloud computing, VLMs run in a virtual environment. Thus, physical infrastructure is not required, making scaling more flexible. This lets organizations focus on improving the VLMs rather than just managing the tech.
With the growing presence of VLMs, further advancements are anticipated in virtual environment solutions and cloud computing services, which will provide enhanced processing and understanding of visual data. ironment solutions and cloud computing services. This will make processing and understanding visual data even better.
| Benefits | Description |
|---|---|
| Improved Accuracy | Enhanced ability to recognize patterns and relationships in visual data |
| Increased Efficiency | Reduced processing time and improved scalability |
| Flexibility | Ability to deploy and manage VLMs in a virtual environment |
Architecture of Visual Language Models
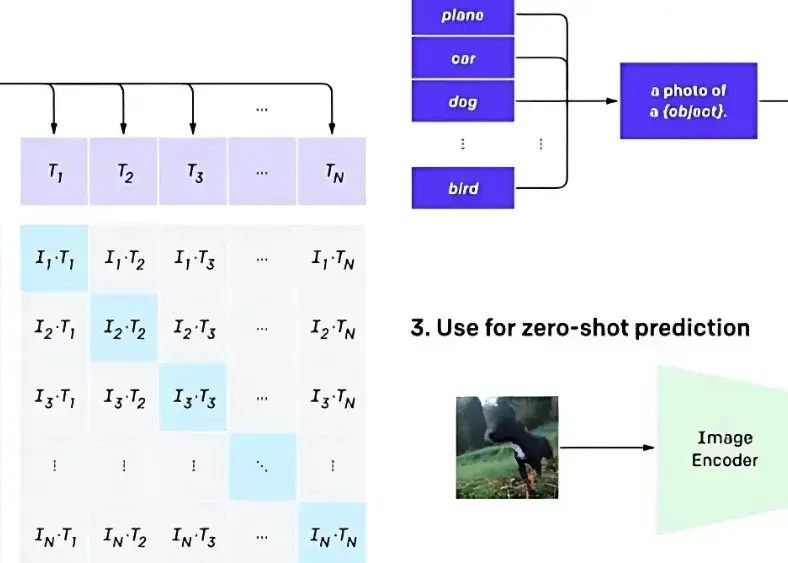
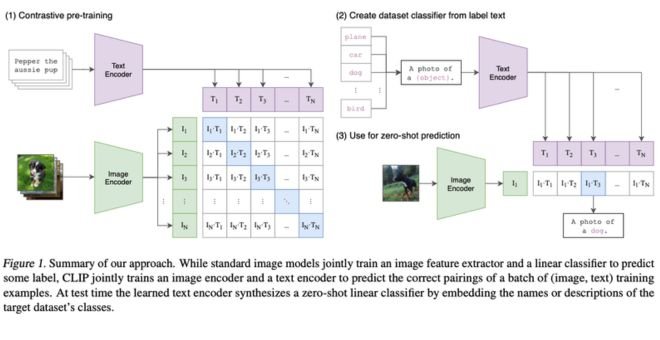
Different types of visual language Models (VLMs) based on how they bind visual and textual data have early fusion, intermediate fusion, or late fusion architectures.
VLMs may act as very much similar to large language models that can take in both visual and textual inputs. The basic idea is the same here, but the architectural details differ: images and text shall become one representation, say, embedding, and inference shall be performed for this joint input. These embeddings are the vectors of tokens numerically encoding their semantic information.
Focus on LLaVA
Among several of the open-source VLMs that can be made available, LLaVA (Large Language and Vision Assistant) is one example and has actually a pretty good multimodal model very much curated towards visual and language comprehension integrated seamlessly. The one introduced first in the paper, “Visual Instruction Tuning,” by Liu of Columbia University, works by attaching a vision encoder to the Vicuna language model-the latter being an expansion of the Llama 2 architecture.
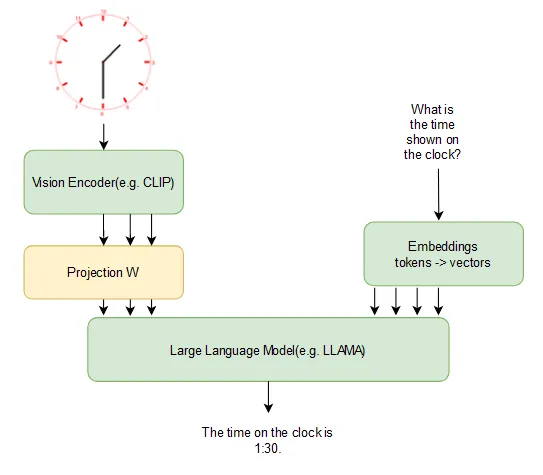
LLaVA’s Architecture
The framework of LLaVA unifies CLIP ViT-L/14 pre-trained vision encoders with language models such as Vicuna. The vision encoders convert images to embedding vectors by extracting sharp meaningful visual features, while embedding corresponds to text within the Vicuna. These two embeddings exist within the same dimensional space, making seamless fusion possible for visual and textual data in order to enhance multimodal comprehension.
Training Phases of LLaVA
There are two major training stages for LLaVA:
Feature Alignment Pre-training: This stage is mainly about updating the projection matrix using data from the CC3M corpus in order to improve the connection between the text modality and the visual modality.
End-to-End Fine-tuning: This stage fine-tunes both the projection matrix and the language model for different applications:
- Visual Chat: Fine-tuned with multimodal instruction-following data for user-friendly interactions.
- Science QA: Fine-tuned using a specialized dataset for scientific reasoning tasks.
Components of LLaVA
LLaVA makes use of multiple models that can decode the visual input along with their textual inputs effectively.
Vision Encoder
Visual encoders segment the two-dimensional images into smaller patches of sizes, say, 16×16 pixels, forming such a number of patches as possible, to convert these patches into numerical vectors that can best encapsulate the image features. Such vectors are then processed through a series of encoder blocks containing feedforward and attention layers, transferring the image representation iteratively.
They aim to align the vector representation of the images much more closely with that of the textual descriptions within the creation of a strong multimodal embedding.
Embedding Models
Embeddings are compact, numerical representations of tokens that depict its semantics; these vectors are assigned by digging up the cooccurrence context in which the tokens appear to be following, reflecting the distributional hypothesis. In this way, the model will be able to capture the semantic relatedness and hence provide reasonable embeddings for new unknown tokens. This is similar to what humans would do while trying to make inferences about semantics as they recognize meaning in context.
Inference with LLaVA
During inference, LLaVA brings together the embedding vectors stemming from both modalities (image and text) then feeds that into a large language model endowed with attention layers, allowing it to dynamically attend to particular parts of the input depending on the particular task. Hence, the context-sensitive nuanced predictions are modeled dynamically to ensure that both visual and linguistic synergies are bridged.
Real-World Applications of VLMs in Industry
VLMs are transforming the lives of people in other industries. They are applying them more and more in e-commerce, healthcare, and manufacturing. The VLMs aid in developing visual search engines, medical image analysis, and quality-control systems.
VLMs – Companies that make them, for example, e-commerce giants Google and Microsoft, allow any business to build its own application. A visual search engine, for example, already lets customers find images of products and make an intangible purchase using these.
See how they really come into use across sectors:
- E-commerce: search engines for visual products, recommendation systems for products.
- Healthcare: Analysis of medical images, diagnosing diseases.
- Manufacturing: Systems for quality control, detection of defects.
Extremely large data and accurate processing and using VLMs are performed. Companies can choose the most preferred supplier among many.
The VLM is destined to alter a lot of industries with its solutions that are innovative. Much more will be determined by VLM evolution in the coming days to excite the minds of inventiveness.
| Industry | VLM Application | Benefits |
|---|---|---|
| E-commerce | Visual search engines | Improved customer experience, increased sales |
| Healthcare | Medical image analysis | Accurate disease diagnosis, improved patient outcomes |
| Manufacturing | Quality control systems | Reduced defects, improved product quality |
You May Like: What's A Webhook And How Does It Work? With Examples
Performance Metrics and Benchmarking of VLMs
Tools like forensics, accuracy, precision, and reverberation are essential aspects that objectively ascertain the vlm performance. It indicates the ability of vlm to comprehend and categorize sources of numbers as well as make determinations regarding counting and collections. As it is crucial to testing the vlm software, accuracy stands for how often vlm gets it right.
Benchmarking-to compare different software with different vlm and look for improvement standards. Measure the software performance according to a standard dataset. Important metrics include:
- Accuracy
- Precision
- Recall
With these parameters, they would improve their vlm technology. They would.aim to create software that can accurately understand data. This leads to better decisions and outcomes.
Integration Challenges and Solutions
It is tough to integrate Visual Language Models(VLMs) into the current systems. It includes resource and technical challenges. Coordinating their working with the already established systems and designing custom APIs are gigantic tasks. In addition, VLMs take a lot of processing and memory to work, a huge dent on one’s pockets.
Handling big data and traffic is yet another overwhelming challenge. Virtual location managers and virtual location management services are of help here. They provide the know-how expertise and power facilities needed for this smooth integration.
By applying virtual location managers and virtual location management services, one can realize the following benefits:
- Scalability and Performance
- Compatibility with existing infrastructure
- Expertise and resources
| Challenge | Solution |
|---|---|
| Technical implementation hurdles | Custom API development, compatibility testing |
| Resource requirements | Access to computational power, memory, and expertise |
| Scalability considerations | Load testing, performance optimization |
Utilizing Vision Language Models with Transformers
To perform inference using the LlavaNext model, follow these steps:
Initializing the Model and Processor
First, import the necessary libraries and set up the model and processor:
pythonCopy codefrom transformers import LlavaNextProcessor, LlavaNextForConditionalGeneration
import torch
# Determine the device (GPU if available, otherwise CPU)
device = torch.device('cuda' if torch.cuda.is_available() else 'cpu')
# Load the processor and model from the pre-trained resources
processor = LlavaNextProcessor.from_pretrained("llava-hf/llava-v1.6-mistral-7b-hf")
model = LlavaNextForConditionalGeneration.from_pretrained(
"llava-hf/llava-v1.6-mistral-7b-hf",
torch_dtype=torch.float16,
low_cpu_mem_usage=True
)
model.to(device)
Generating Outputs from Images and Prompts
Next, process the input image and text prompt before passing them to the model for generation:
pythonCopy codefrom PIL import Image
import requests
# Load an image from a URL
url = "https://github.com/haotian-liu/LLaVA/blob/1a91fc274d7c35a9b50b3cb29c4247ae5837ce39/images/llava_v1_5_radar.jpg?raw=true"
image = Image.open(requests.get(url, stream=True).raw)
# Define the text prompt
prompt = "[INST] <image>\nWhat is shown in this image? [/INST]"
# Process the inputs
inputs = processor(prompt, image, return_tensors="pt").to(device)
# Generate predictions
output = model.generate(**inputs, max_new_tokens=100)
# Decode and display the results
print(processor.decode(output[0], skip_special_tokens=True))
Fine-Tuning Vision Language Models with TRL
The TRL library now includes experimental support for fine-tuning vision-language models (VLMs). Here, we demonstrate fine-tuning a Llava 1.5 model using a dataset of image-conversation pairs. This dataset contains interactions where each image is accompanied by user queries.
Preparing the Environment
Ensure you have the latest TRL version installed:
bashCopy codepip install -U trl
Setting Up Fine-Tuning
Here’s how to set up instruction fine-tuning:
pythonCopy codefrom trl.commands.cli_utils import SftScriptArguments, TrlParser
# Parse arguments for fine-tuning
parser = TrlParser((SftScriptArguments, TrainingArguments))
args, training_args = parser.parse_args_and_config()
# Define the chat template
LLAVA_CHAT_TEMPLATE = """A chat between a curious user and an artificial intelligence assistant. The assistant gives helpful, detailed, and polite answers to the user's questions. {% for message in messages %}{% if message['role'] == 'user' %}USER: {% else %}ASSISTANT: {% endif %}{% for item in message['content'] %}{% if item['type'] == 'text' %}{{ item['text'] }}{% elif item['type'] == 'image' %}<image>{% endif %}{% endfor %}{% if message['role'] == 'user' %} {% else %}{{eos_token}}{% endif %}{% endfor %}"""
Initializing the Model and Tokenizer
pythonCopy codefrom transformers import AutoTokenizer, AutoProcessor, LlavaForConditionalGeneration
# Load the model and tokenizer
model_id = "llava-hf/llava-1.5-7b-hf"
tokenizer = AutoTokenizer.from_pretrained(model_id)
tokenizer.chat_template = LLAVA_CHAT_TEMPLATE
processor = AutoProcessor.from_pretrained(model_id)
processor.tokenizer = tokenizer
model = LlavaForConditionalGeneration.from_pretrained(model_id, torch_dtype=torch.float16)
Creating a Data Collator
To prepare text-image pairs for training:
pythonCopy codeclass LLavaDataCollator:
def __init__(self, processor):
self.processor = processor
def __call__(self, examples):
texts = []
images = []
for example in examples:
messages = example["messages"]
text = self.processor.tokenizer.apply_chat_template(
messages, tokenize=False, add_generation_prompt=False
)
texts.append(text)
images.append(example["images"][0])
batch = self.processor(texts, images, return_tensors="pt", padding=True)
labels = batch["input_ids"].clone()
if self.processor.tokenizer.pad_token_id is not None:
labels[labels == self.processor.tokenizer.pad_token_id] = -100
batch["labels"] = labels
return batch
data_collator = LLavaDataCollator(processor)
Loading the Dataset
pythonCopy codefrom datasets import load_dataset
# Load the dataset
raw_datasets = load_dataset("HuggingFaceH4/llava-instruct-mix-vsft")
train_dataset = raw_datasets["train"]
eval_dataset = raw_datasets["test"]
Training the Model
Initialize the trainer and start training:
pythonCopy codefrom trl import SFTTrainer
trainer = SFTTrainer(
model=model,
args=training_args,
train_dataset=train_dataset,
eval_dataset=eval_dataset,
dataset_text_field="text",
tokenizer=tokenizer,
data_collator=data_collator,
dataset_kwargs={"skip_prepare_dataset": True},
)
trainer.train()
# Save and push the model
trainer.save_model(training_args.output_dir)
trainer.push_to_hub()
Cost-Benefit Analysis of VLM Implementation
This is just one way by which Visual Language Models may achieve efficiency for almost all kinds of jobs, ranging from generalistics to specific and field-relevant jobs. In fact, it is using costs to compare benefits for all the activities utilizing VLMs that shows convincingly whether all these activities are money-wasting or not.
Vlm brings better customer service, more money, and reduced costs. Vlm developer tools like SDKs and APIs can improve benefits and reduce costs by implementing VLM solutions tailored specifically to an organization.
For doing a cost-benefit analysis, some of the key items of concern for the cost:
- Development costs: The expenses incurred in development and installation of a VLM solution.
- Deployment costs: The costs incurred in deploying a VLM solution to incorporate some of these other systems.
- Maintenance costs: The costs associated with operating a VLM solution and running updates.
- Benefits: The advantages accrued such as greater efficiency, more accurate, and good customer service.
By analyzing these points, it may create a sign to consider whether the use of a VLM solution is valiant. With the right tools and proper vlm strategy, it can make the best use from VLMs. This has huge bottom line improvements on how things work, how accurate they are, and how happy customers are. most out of VLMs. This leads to big improvements in how things work, how accurate they are, and how happy customers are.
Best Practices for VLM Adoption
The need of adopting Visual Language Models (VLMs) is also identified with proper planning and maintenance. The really effective means of adopting vlm applications is the enhancement of business operations and decision-making. Already established companies such as Google and Microsoft provide their customers with pre-trained models and APIs so that they can easily use VLMs when required.
An elaborate plan of the adoption of a VLM entails the following:
- A clear plan on the use of the VLM, objectives and timelines.
- Train users to effectively use and maintain VLM.
- Set up a program of regular updates and security checks for VLM.
Implementation Strategy
A detailed plan is a prerequisite to the success of VLM. This refers to inventorying existing systems, understanding where VLMs can be integrated to add value, and laying down a roadmap for addition.
Team Training Requirements
Training teams well is critical to upholding the use of VLM. Training and support are provided by VLM vendors to help organizations with onboarding.
Maintenance Protocols
Keeping VLMs current and secure is very important: updates, threat monitoring, and regular checks prevent pro-blems.
Measuring Success: KPIs for VLM Implementation
It’s imperative to consider key performance indicators (KPIs) regarding the evaluation of how effective exactly Visual Language Models (VLM) are. These KPIs not only point out how VLM tools perform but also enable an organization to check the tools’ business impact. Tracking KPIs allows a business to make an assessment whether VLM had an encouraging input in areas related to efficiency, accuracy, and overall performance. They could further attain benefits related to, say, measuring where to point their VLM improvements.
One such KPI that should be measured is ROI or Return on Investment. ROI assesses the economic side or the business profit of VLM implementation vis-a-vis savings accrued or generated by the tool in operational terms- labor costs, efficiency improvements in operations, or possible new revenue streams. Positive ROI indicates that the tools are, indeed, having an effect on the bottom line and, therefore, justify their investment. Another KPI would be customer satisfaction-these give a point of how customers perceive services earned through VLM. This can even include the claims of responsiveness and accuracy of these services through VLM. Higher satisfaction rates may indicate that VLM technology is thus meeting most of the user’s expectations, while lower scores indicate necessary improvements in operations or interaction with users.
Another important parameter of performance is accuracy and precision. Accuracy will tell how it is represented or portrayed vis-a-vis real-world visual data interpretation and processing by a visual language models model. Precision, on the other hand, will measure the reliability and consistency of the outputs from the model. These industrial metrics will play a vital role in areas where data integrity is very important like in healthcare, security, and autonomous vehicles. It is through monitoring these KPIs that organizations will be able to find where their Visual Language Model implementation is excelling or failing. This, in turn, helps make the right choice for an optimized system that aligns more with business objectives. In the end, performance against these critical parameters ensures that VLM technology eventually continues giving tangible benefits for the organization and keeps it on the success and growth track.
KPI Table for VLM Performance Evaluation
| KPI | Description |
|---|---|
| Accuracy | Measures the correctness of VLM interpretations. |
| Precision | Evaluates the precision of VLM processing. |
| Recall | Assesses the ability of VLM to detect relevant information. |
Common Pitfalls to Avoid When Deploying VLMs
Deploying a Visual Language Model (VLM) in-house is really challenging. These models are very sophisticated and require an extraordinary amount of planning and execution to work optimally. One of the major challenges that firms face is having a shortage of training data. The performance of the VLM varies significantly based on the kind of data used to train it so that the performance will be inferior if there is no good-quality relevant data available for usage in training the VLM. For performance optimization of the VLM, the data that would be used for training needs to be as diverse, high-quality, and representative as possible. A common pitfall is insufficient computation power. VLMs are highly resource-dependent applications that require extremely powerful hardware and infrastructure to support their complex computation. Organizations that do not invest in that level of computing power may experience delays or degraded performance that can cause catastrophic impacts.
Besides, they do not consider much the demand of the task when brought into use VLM deployment. Some VLMs are certainly good for accepting one kind of task and not the other. One can expect the underperformance of VLM in performing the task when the task complexity is not comparable with its capability. Evaluation of VLM suitability for performing a given task before deploying it is one major thing to ensure the desired success. Another mistake is that the organizations do not evaluate the performance of VLM after its deployment. By continuously checking on the working of the model in real conditions, it helps in pin-pointing areas for improvement and ensures survival of the performance in the future. Regular performance review based on standard KPIs helps organizations keep their VLM systems healthy and avoid a problem.
However sufficient service and maintenance of VLM is also much necessary for the long-term profit of one. Like any technology, VLMs will need to be updated and maintained from time to time, so that they will keep pace with the changing needs and new data requirements. Organizations that do not invest in support or maintenance will soon find themselves running into operational problems in the form of stale models and lackluster performance. Virtual location managers and all services associated with them are the significant facets that prevent organizations from falling into this unfortunate trap. Such specialists offer detailed guidance and resources which can ensure proper deployment of the VLM, seamless integration with existing systems, and continuous optimization for maximum performance. In addition, virtual location management services also help organizations to intervene when challenges occur, performance monitoring, and efficiency maintenance of the system over time. Recognizing and addressing these common pitfalls is an excellent way of putting organizations in a good position for successful installations of their VLMs, which will deliver on future expectations and overall business objectives.
Conclusion: The Future of Visual AI Processing
The future of visible language processing technology is changing so quickly. New developments in deep learning and computer vision have contributed to the enhancement of visual AI processing. Such applications promise to filter into every other area, including e-commerce and healthcare. With the capability to learn from very voluminous datasets and ways of improvement over time, VLMs will change our perception and application of visual data, be it a search engine or even image recognition and analysis. With the adoption of VLMs into more businesses, keeping up with the latest technology and its applications will thus be required. This would empower organizations to innovate more and become efficient while also enhancing their customer service.
FAQs
Q: What are Visual Language Models (VLMs) and how do they work?
A: VLMs are high-level models that can process images and text. They transform how we think about computers and search mechanisms.
Q: What are the core components of VLMs?
A: VLMs have three main parts. A vision encoder handles images, an embedding projector aligns images and text, and a text decoder creates text from input.
Q: How has the evolution of visual AI processing led to the development of more sophisticated VLMs?
A: Advances in visual AI have made VLMs smarter. They learn from big datasets and get better over time. Deep learning, natural language processing, and computer vision are key to their success.
Q: What are the benefits of VLMs in the field of digital vision?
A: VLMs are changing digital vision by letting computers understand images. This makes things more accessible, improves user experience, and boosts efficiency.
Q: What is the technical architecture of modern VLMs based on?
A: Modern VLMs use neural networks, trained on large datasets. This lets them learn from images and text. CNNs and RNNs are at the heart of this technology.
Q: How do VLMs process and interpret visual information?
A: VLMs use computer vision and deep learning to understand images. They can spot objects, scenes, and actions in pictures and videos.
Q: What are some real-world applications of VLMs in industry?
A: VLMs have many uses in industries like e-commerce, healthcare, and manufacturing. They help in visual search engines and analyzing medical images for disease diagnosis.
Q: How are the performance of VLMs evaluated?
A: VLMs are checked using metrics like accuracy and precision. These show how well VLMs can classify and understand images and text.
Q: What are some of the integration challenges and solutions for implementing VLMs?
A: Adding VLMs to systems can be tough due to technical and resource issues. Ensuring compatibility and developing APIs are key. Also, lots of computing power and memory are needed to train and use VLMs.
Q: What are the key considerations for the cost-benefit analysis of VLM implementation?
A: When deciding on VLMs, weigh the costs against the benefits. Benefits include better customer service, more sales, and cost savings. Costs include development, deployment, and upkeep.
Q: What are the best practices for VLM adoption?
A: To adopt VLMs well, have a clear plan, train your team, and set up maintenance. There are pre-trained models and APIs available for custom applications.